Machine Learning Flow
머신러닝 기본 Flow를 위한 아키텍처
아키텍처 소개
인공지능(AI)는 컴퓨터 기술의 발달과 함께 빅데이터를 기반으로 스스로 패턴을 찾아내고, 미래에 대한 예측이 가능한 형태로 발전해 왔습니다. 인공지능(AI)을 비즈니스에 적용시키기 위해서는 먼저 과거 데이터에 대한 수집과 분석이 선행되어야 합니다. 사용자의 경험 기반 데이터나 산업 특성의 대용량의 데이터에 대해 머신러닝 알고리즘을 적용시켜 특정 모델을 도출하고, 미래의 행동을 예측하거나 물류의 속도, 품질의 최적화에 대한 신뢰할만한 결과를 도출할 수 있고 이를 기반으로 적합한 의사결정을 할 수 있습니다. 클라우드 환경에서는 기본적인 머신러닝을 위한 인프라를 즉시 구성할 수 있고 활용할 수 있어 머신러닝을 위한 새로운 인프라를 직접 구성할 필요가 없어 매우 효율적입니다. 빅데이터 분석을 위한 관리형 상품을 이용하거나 대용량의 데이터를 저장하고 관리할 수 있는 스토리지 상품을 필요할 때 사용할 수 있고 사용한 만큼 비용을 지불할 수 있는 합리적인 가격으로 사용할 수 있습니다.
아키텍처
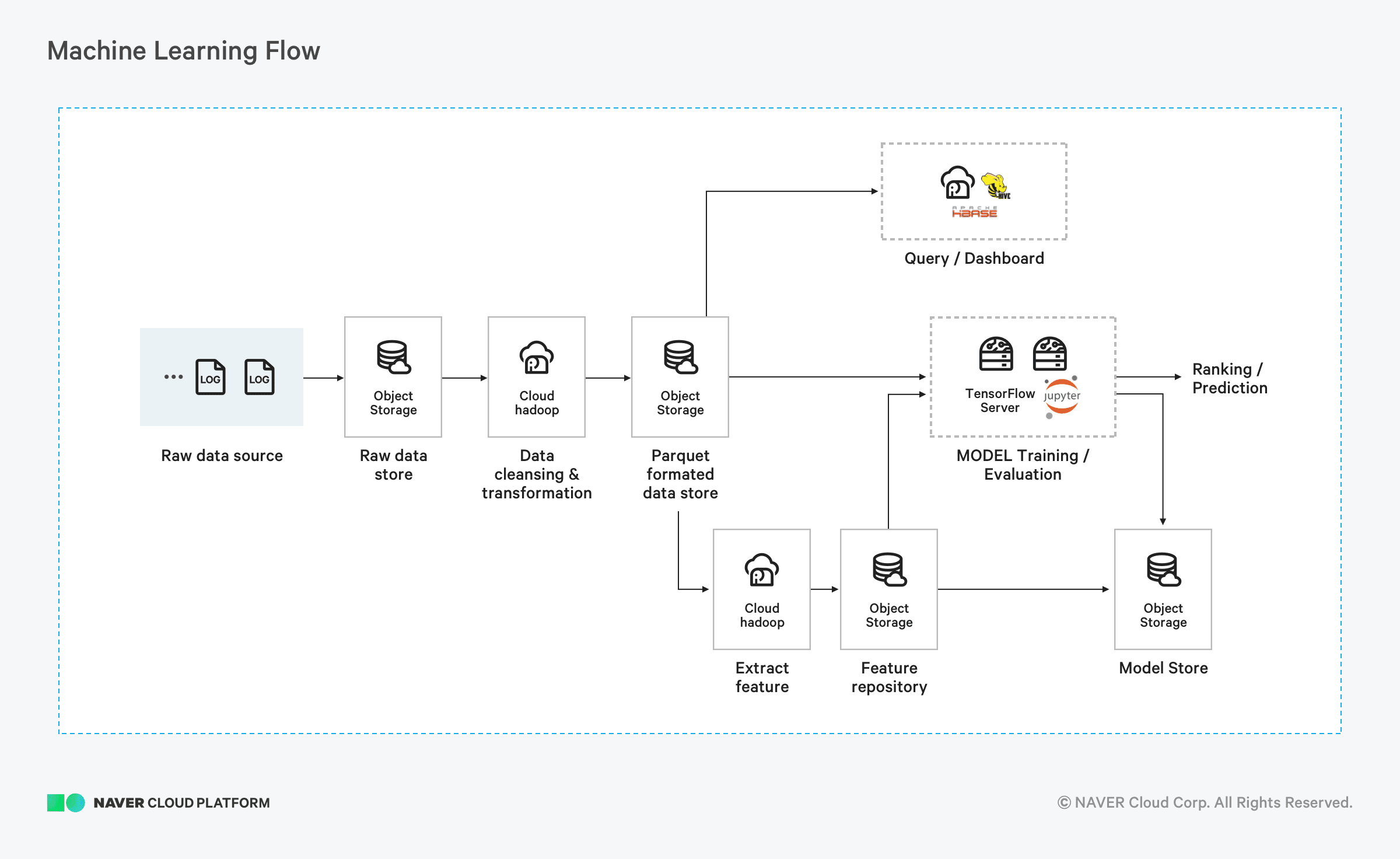
연동 부가 서비스
솔루션 적용 및 비즈니스 효과
- 쉽고 간단하게 클러스터 생성
- Cloud Hadoop은 자동으로 클러스터 생성을 지원하여 인프라 관리 작업에 대한 부담을 덜어드립니다. 여러 오픈 소스 프레임워크 설치 및 구성, 최적화 과정을 통해 언제든 분석 가능한 시스템을 가질 수 있습니다. Hadoop, HBase, Spark, Hive 등의 오픈 소스 프레임워크 설치 되어 있고, 구성이 최적화된 클러스터가 생성되어 사용자는 바로 분석에 필요한 작업을 수행할 수 있습니다
- 유연한 확장성 및 고가용성 확보
- Cloud Hadoop 클러스터 생성시 필수로 2대의 마스터 노드를 제공하고 이중화 구성하여 고가용성을 보장합니다. 마스터 노드 장애시 standby 노드의 역할 변경되어 마스터 노드로의 역할 수행이 가능하고, 사용자 원하는 시간에 데이터 분석에 필요한 인스턴스의 수를 최소 1개에서 최대 8개까지 손쉽게 줄이거나 늘릴 수 있습니다
- 클러스터 관리 및 모니터링을 위한 Web UI제공
- Cloud Hadoop 클러스터에 대한 정보 및 상태를 관리 할 수 있는 UI를 제공합니다. 오픈 소스인 Apache Ambari를 이용해 손쉬운 Web UI 및 REST API 사용을 활용하여 Cloud Hadoop 클러스터의 관리 및 모니터링을 편리하고 효율적으로 할 수 있습니다. 또한 직접 서버에 로그인 하지 않고도 Hadoop, HBase, Spark, Hive 등의 configuration을 자유롭게 할 수 있습니다
- Object Storage 기반의 무제한 데이터 용량 제공
- 데이터 저장소로 네이버 클라우드 플랫폼의 Object Storage를 사용해 저렴한 비용으로 대량 데이터를 저장합니다. 고객의 비즈니스 규모에 따라 GB 단위에서 시작하여 PB 단위까지 합리적인 비용으로 손쉬운 확장이 가능하므로 용량 걱정 없이 사용할 수 있고 Cloud Hadoop에서 데이터를 분석할 수 있도록 연계할 수 있습니다
- 다양한 유형의 컴퓨터 파워 제공
- 다양한 유형의 컴퓨팅 파워를 가진 서버 타입을 제공하므로, 사용자는 분석에 필요한 성능에 맞춰서 다양한 서버를 선택하여 빠르게 대량의 데이터 분석이 가능합니다